
MLP-Mixer: An all-MLP Architecture for Vision
https://arxiv.org/abs/2105.01601
MLP-Mixer (이하 믹서)는 컴퓨터 비전을 위한 MLP만으로 구성된 딥러닝 모델이다.
1. Introduction
컴퓨터 비전 분야에서는 convolution 연산에 기반한 CNN 모델이 주름잡고 있다. 한편 자연어 처리 분야에서 RNN 이후 널리 활용되는 attention 기반의 transformer 구조를 컴퓨터 비전 분야에 접목하여 탄생한 Vision Transformer (ViT)는 state-of-the-art performance를 달성했다.
본 논문에서는 가장 기본적인 인공신경망인 MLP (Multi-layer perceptron)을 활용한 믹서를 제안한다. 믹서는 convolution이나 self-attention을 사용하지 않지만, SOTA에 가까운 퍼포먼스를 얻을 수 있었다.
2. How?
- Image as a sequence of patch.
- Mixing in a) channel, and b) token.
3. Ideas
3.1 Image as a sequence of patch.
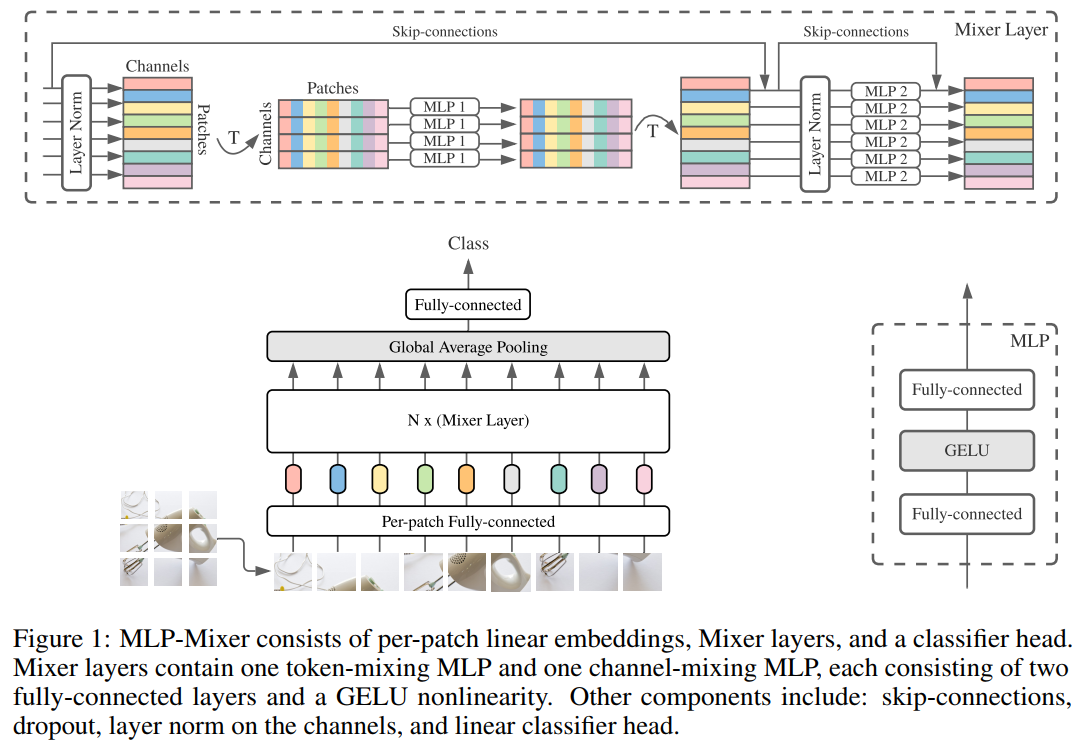
기존 CNN 모델은 이미지를 W (가로) x H (세로) x C (채널)의 텐서로 보고 컨볼루션 연산을 통해서 W’ x H’ x C 의 지역적 특성들을 추출하여 활용함. 따라서 컨볼루션 레이어가 stacking 됨에 따라서 상위 레이어에서 필터가 커버하는 범위 (receptive field)가 증가함. MLP-mixer는 이미지를 겹치지 않는 작은 패치들의 시퀀스로 봄. 즉 W x H x C의 텐서가 S x C’ 텐서로 바뀌는데, S는 이미지 패치의 수, C’은 패치로부터 추출된 feature임. 예를들어 전체 이미지를 16 x 16 pixel의 이미지 패치로 전부 자르고, 각 패치는 NLP에서의 워드 임베딩 처럼 C’ 차원의 벡터로 즉 토큰 (token)으로 변환됨. 여기서 토큰으로의 변환은 projection matrix를 통한 linear transformation임.
3.2 Channel mixing and token mixing MLP.
Mixer 레이어는 MLP를 통해서 channel mixing operation과 token mixing operation을 수행함. 따라서 per-location operation과 cross-location operation을 explicit 하게 분리함.
token-mixing MLP는 채널을 고정시키고 (S x 1), MLP를 통한 nonlinear transform을 수행해서 다시 (S x 1) 벡터를 얻음. 각 패치는 특정 location에 대한 정보를 가지고 있고 채널이 고정된 상태이므로 token-mixing MLP는 특정 채널에서 패치들 사이의 관계를 학습하여 cross-location operation임.
channel-mixing MLP는 패치를 고정시키고 (1 X C’), nonlinear transform을 수행한 (1 x C’) 벡터를 얻음. 패치가 고정되어있기때문에 location의 특징을 고려하여 per-location operation임.
각각의 연산에서 skip connection과 layer normalization을 포함하고 있음.
전체적인 구조는 그림과 같음.
 |
| * Mixer 구조 * |
댓글남기기